How to load and run projects
Explains how to load example projects into JIPipe.
This tutorial assumes that you have installed JIPipe. If you want information on how to setup our software, please visit the installation guide.
Table Of Contents
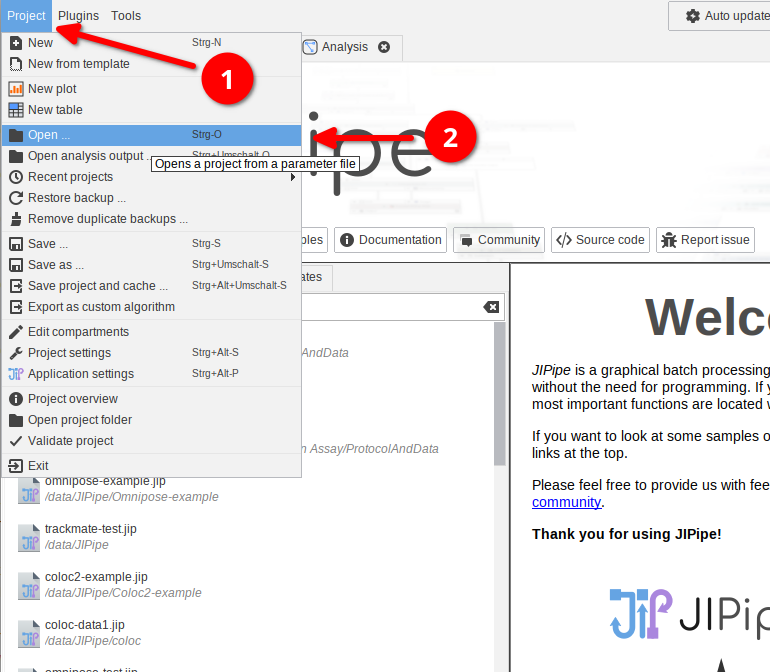
Loading: Step 1
- If you downloaded a
*.zipfile, please extract it first - Open JIPipe
- Navigate to
Project > Open
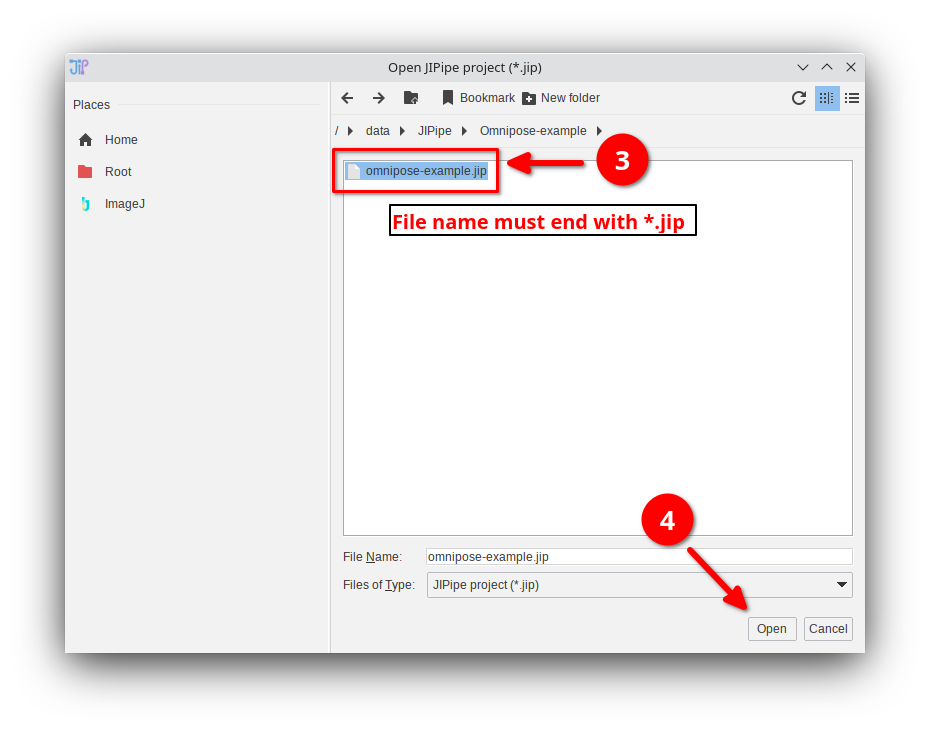
Loading: Step 2
- Select a file that ends with
*.jip - Click
Open
*.jip files are typically located either directly in the root directory of the package, or within a subdirectory ProtocolAndData.

Loading: Step 3
You will have two options:
This windowwill open the project in the current windowNew windowwill create a new JIPipe window for the project
Choose the option that is most convenient for you.
Afterwards, the project will be opened in the JIPipe editor.
To execute the pipeline, you have two options:
- Running the whole pipeline: 👉 this is recommended for running finalized pipelines on the full dataset
- Caching specific nodes or compartments: 👉 use this option if still want to modify the pipeline or want to review intermediate results
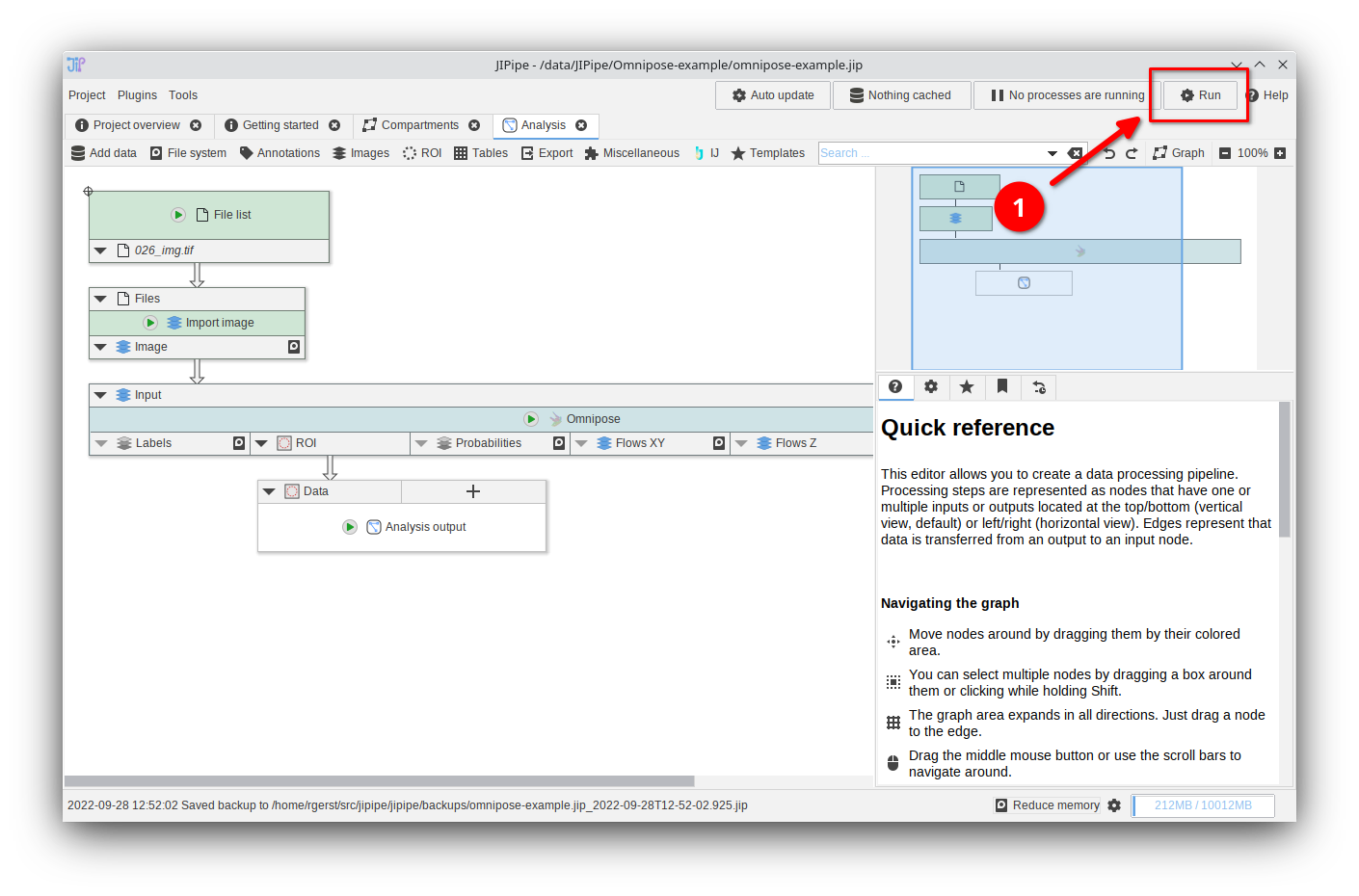
Running the whole pipeline: Step 1
To run the whole pipeline, click the Run button at the top right.
Running a pipeline will store the results to the hard drive. While the generated directory structure can be browsed by humans, it is mainly designed to be opened by the JIPipe result browser.
If you want to re-open a generated results directory, navigate to Project > Open analysis output
If you intend to export files in a form that is more suitable for humans, please check out our tutorials.
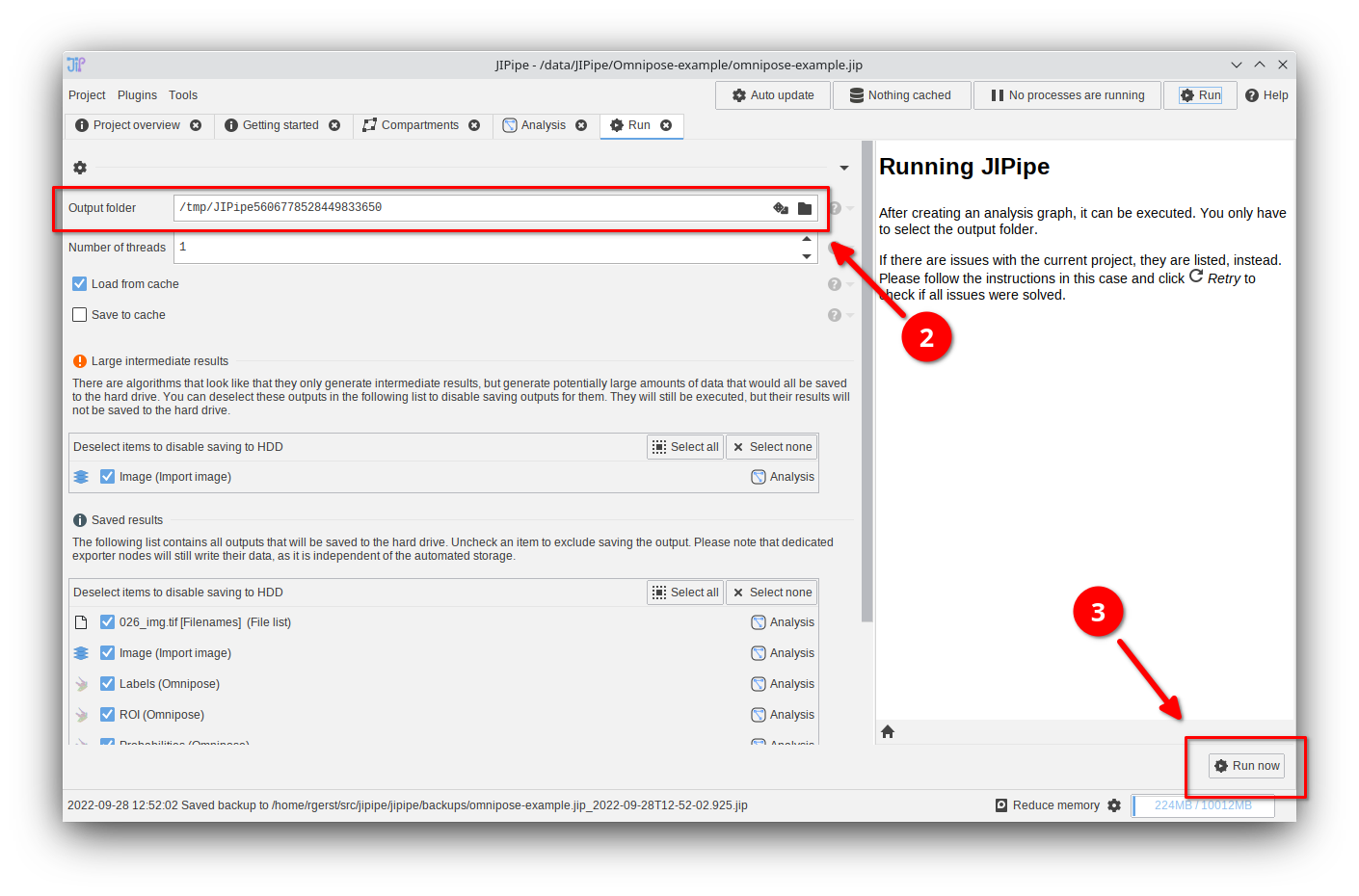
Running the whole pipeline: Step 2
Please choose an empty output directory or leave the default setting (temporary folder).
Proceed by clicking Run now.
Running the whole pipeline: Step 3
Please choose an empty output directory or leave the default setting (temporary folder).
Proceed by clicking Run now.
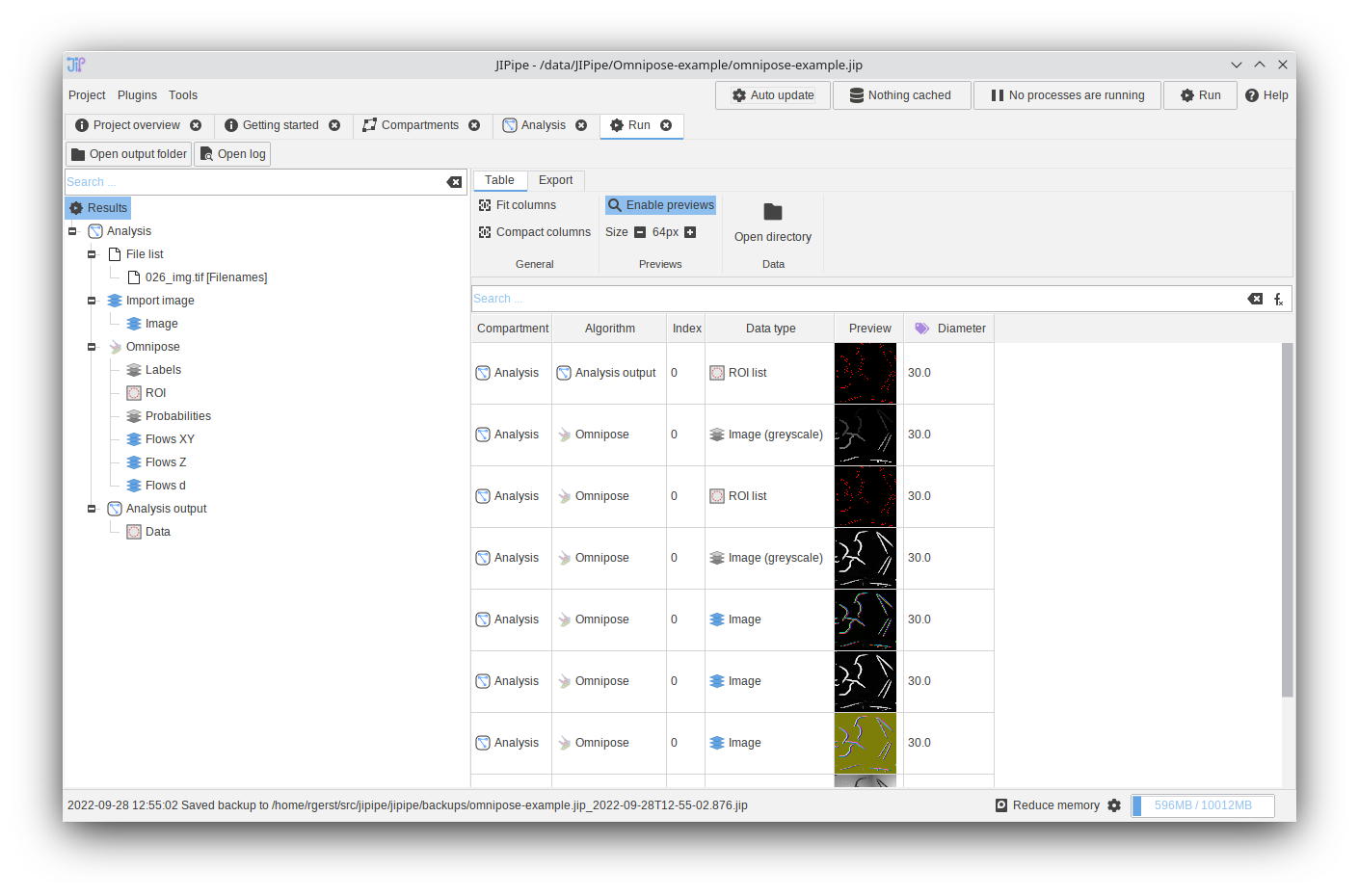
Running the whole pipeline: Step 4
You now can browse through the generated results.
Double-click items to open them in JIPipe or ImageJ (depending on the data type).
If you want more information about the result browser, please visit the result browser documentation.
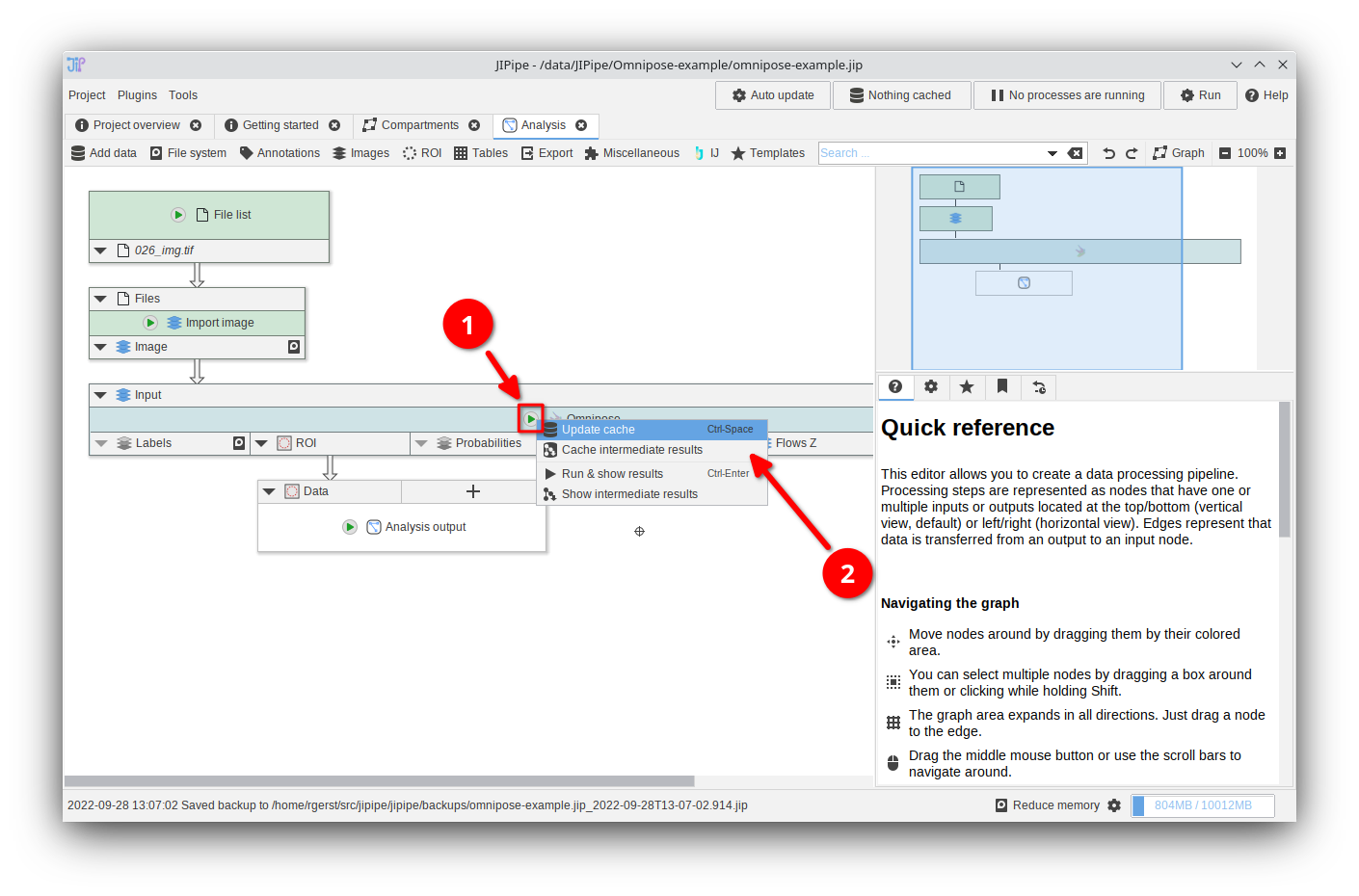
Running/caching nodes: Step 1
To run a specific node or compartment, click the button that is located on the node. Afterwards, select one of the options:
Update cachewill run the pipeline up to the selected node and store only the results of the selected nodeCache intermediate resultswill run the pipeline up to the selected node, but also store all results of all predecessors
Choose the option that is most convenient for you.
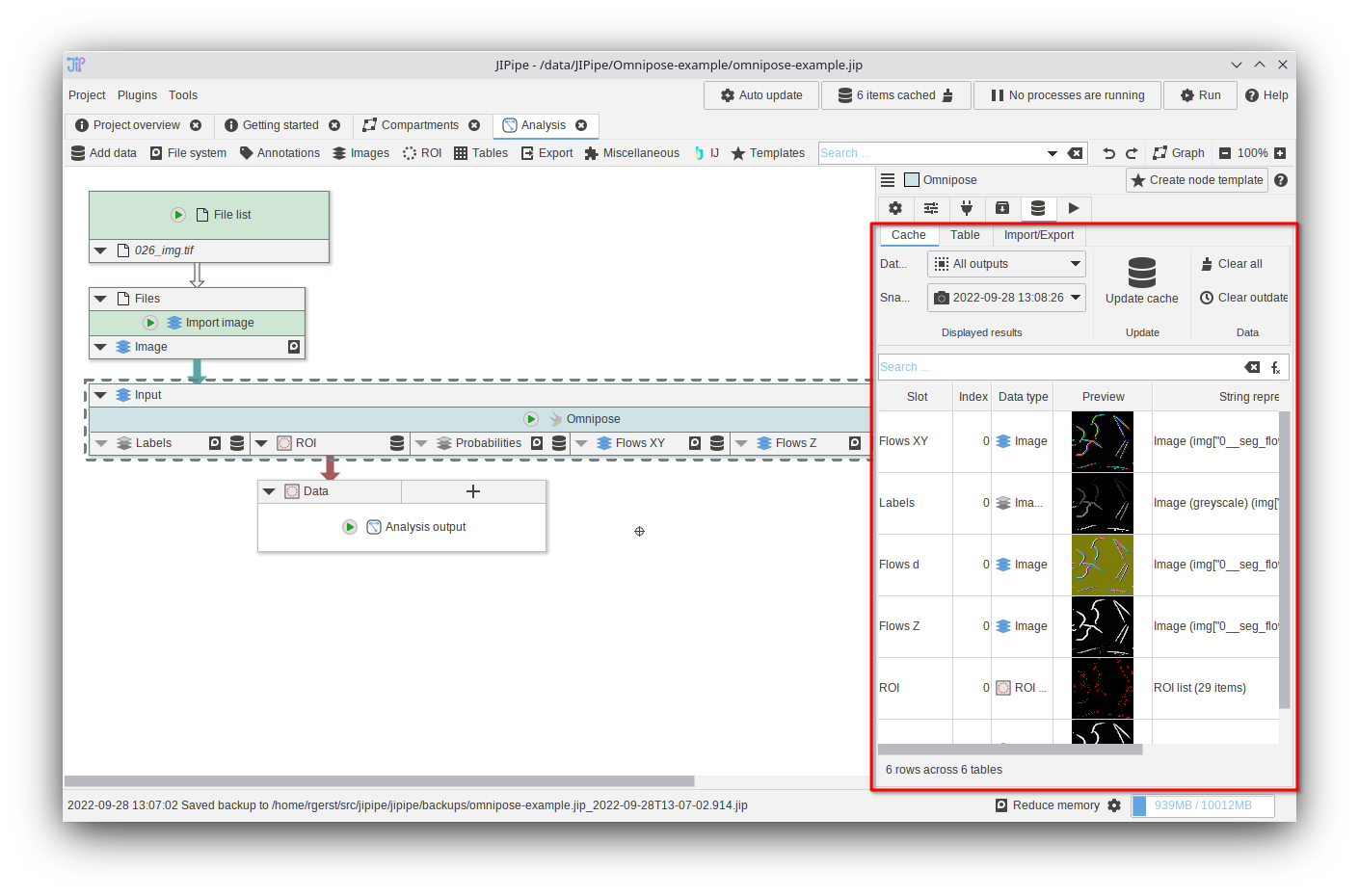
Running/caching nodes: Step 2
You now can browse through the generated results.
Double-click items to open them in JIPipe or ImageJ (depending on the data type).
If you want more information about the cache browser, please visit the tutorials.