Download JIPipe 3.0.0



The version was pushed to 3.0.0 according to Semantic Versioning due to breaking changes in the Java API.
JIPipe 3.0.0 focuses on overhauling the workflow runtime and user interface.
Upgrade notes
Users
- Custom expression variables/custom filter variables: the variables are automatically transferred to a new standardized storage location. Parameter references to custom variables will become invalid. Use the editor to update the ID or re-add the reference.
- Many UI elements were renamed or changed the location
- Loop nodes are deprecated and are not used anymore to create loops. You can remove Loop start/end nodes. Please take a look at the runtime partition function (see below) to create loops in your pipeline
- Parallelization moved into runtime partitions
Developers
- JIPipeJavaExtension was renamed to JIPipeJavaPlugin, which prevents older plugins from being discovered and loaded
- The execution of pipelines was fully redesigned and utilizes only JIPipeGraphRun instead of two separate implementations
- Many annotation class names were renamed:
- @JIPipeDocumentation →@SetJIPipeDocumentation
- @JIPipeInputSlot →@AddJIPipeInputSlot
- @JIPipeOutputSlot →@AddJIPipeOutputSlot
- @JIPipeNode →@ConfigureJIPipeNode
- …
Runtime partitions
Additionally to graph compartments, which are a visual mode to partition the graph, we introduced runtime partitions as way to partition a pipeline on a functional level. This means that partitions can cross compartments.
The partition of a node is indicated by the color behind the node’s icon and the arrow color. The default partition has no color, thus preserving the design of existing pipelines.
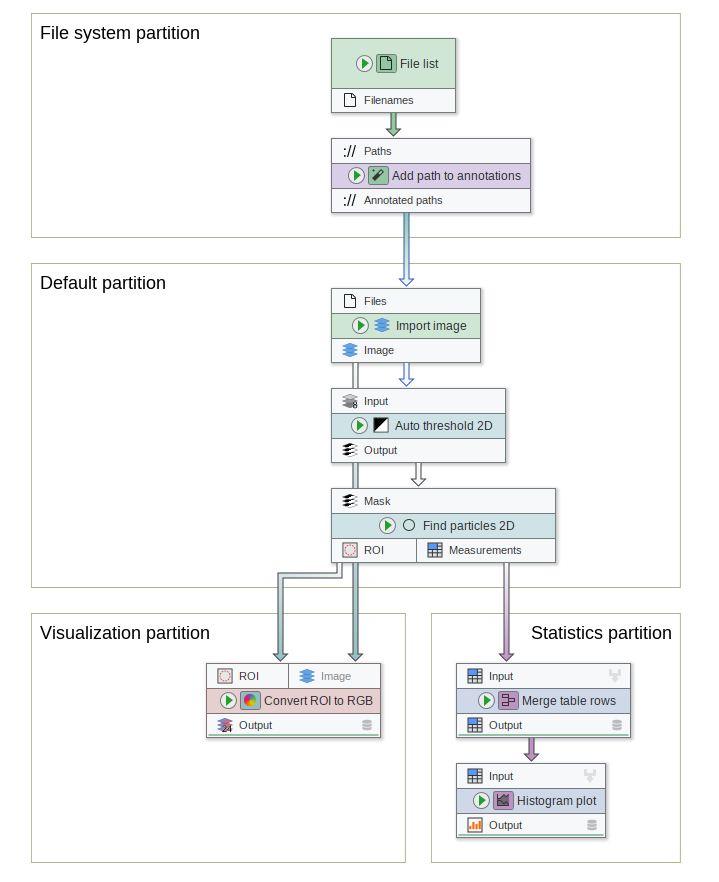
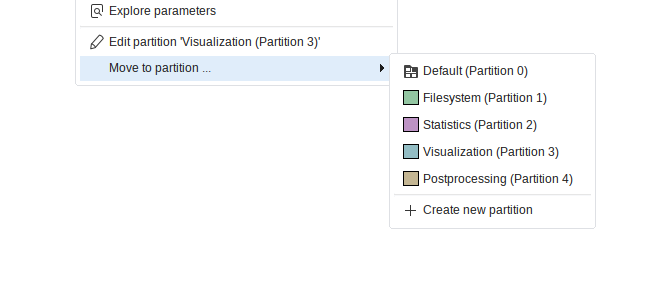
Nodes are partitioned by their right-click menu or the parameter panel. Each pipeline comes with the predefined non-default partitions “Filesystem”, “Statistics”, “Visualization”, and “Postprocessing”. Additional partitions can be created via the parameter panel, context menu, or the project settings.
The new JIPipe graph run algorithm utilizes the partitions to create a hyper-graph (similar to the compartments). Nodes of the hyper-graph are executed in topological order, meaning that all nodes of one partition need to be executed before any node of a dependent partition.
Nodes of a partition do not need to be connected:

Partitions allow to apply various settings in bulk, including the setup of parallelization, export of results, and creation of loops.
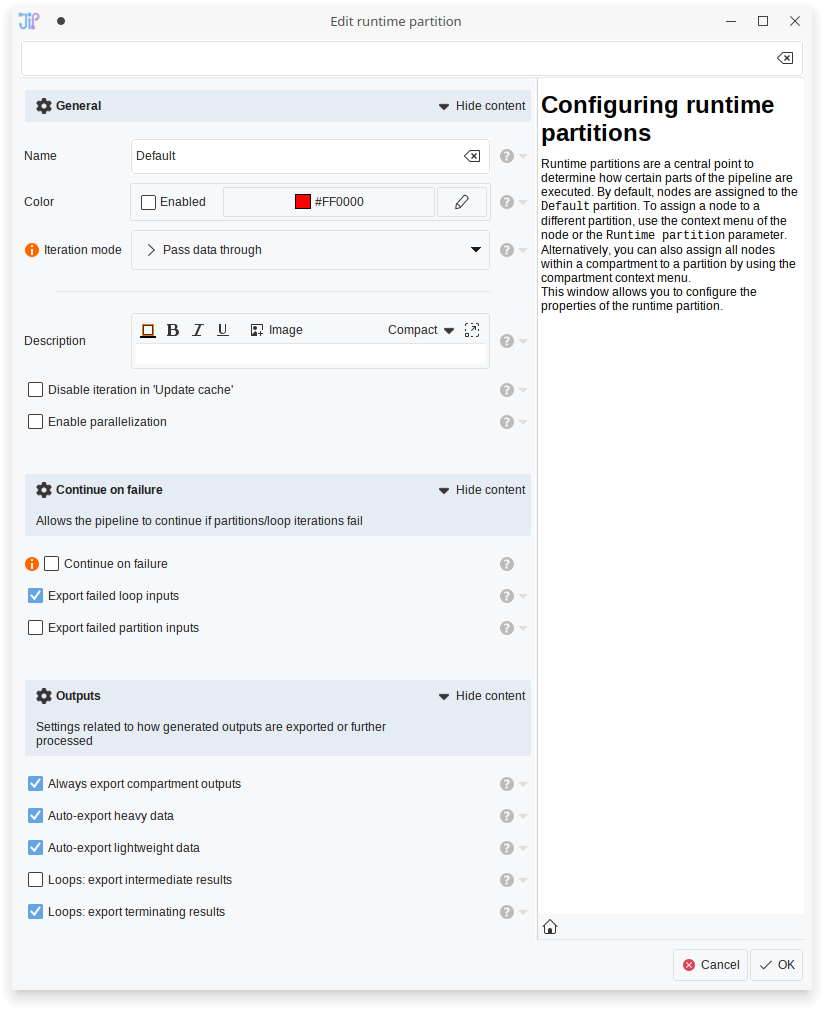
Loop setup
Runtime partitions are replacing loop nodes as mode to loop parts of the pipeline to limit memory consumption. This is achieved by setting the iteration mode to Loop (single data per slot) or Loop (multiple data per slot).
The difference between those two option is that with Loop (multiple data per slot), each loop iteration can receive multiple data per input as grouped by annotations. With the other option, the runtime will split iteration steps that each input only receives exactly one item.

👉 Currently there is no way to debug the loops (input manager), so we recommend to carefully review the settings and which data is put into each step.
👉 Use conversion to data tables & unpacking if you need more control
👉 While the storing into the cache is possible with looped partitions, JIPipe will not be able to query data from the cache if within a loop. The reason behind this is that cached data items currently do not store information about the loop iteration
Continue on failure
You can setup partitions to ignore loop iterations or whole partitions (if loops are disabled) if an error occurs. This is for example useful if the pipeline is intended for end users that might provide data with unexpected properties.
If “Continue on failure” is enabled, JIPipe will continue with the next loop iteration (loops) or pass empty data as output (for non-looped partitions). The default behavior on a failed loop iteration is that JIPipe will export the iteration graph plus the input data of the loop. For failed partitions, JIPipe will not create this backup unless enabled in the runtime parameter settings.
If a failure occurs, both a message and a notification are added to the log.
New design
The user interface was updated to follow more closely modern user interfaces. The colors, spacing, and borders of interface elements were updated. A new icon set based on FontAwesome 6 and the Fluent icons was integrated. A new splash screen, welcome screen, and info header background images were created. Many tabbed interfaces were updated to utilize left- or right-aligned tabs to make the options easier readable. The JIPipe logo was also updated.
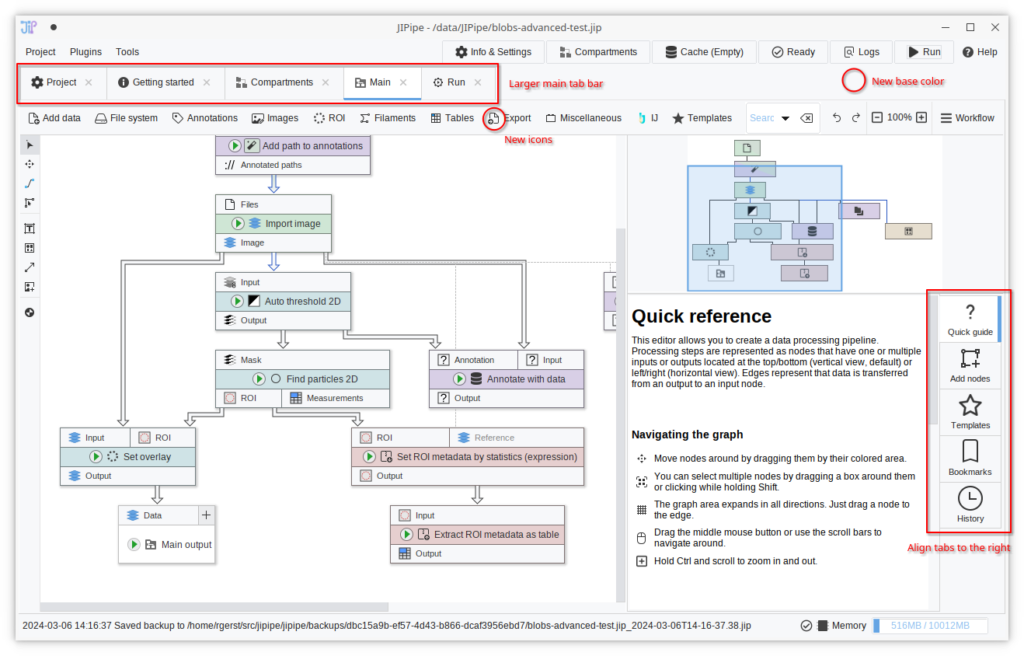
Improved pipeline editor side bar
The sidebar of the pipeline editor was reworked to feature right-aligned tabs, thus making it easier to navigate through the various options. The toolbar located at the top of a selected node’s sidebar was removed to save vertical space. Instead, the associated functionality and additional features were condensed into a new tab “Overview” that provides brief information about a node and gives access to some commonly utilized operations.
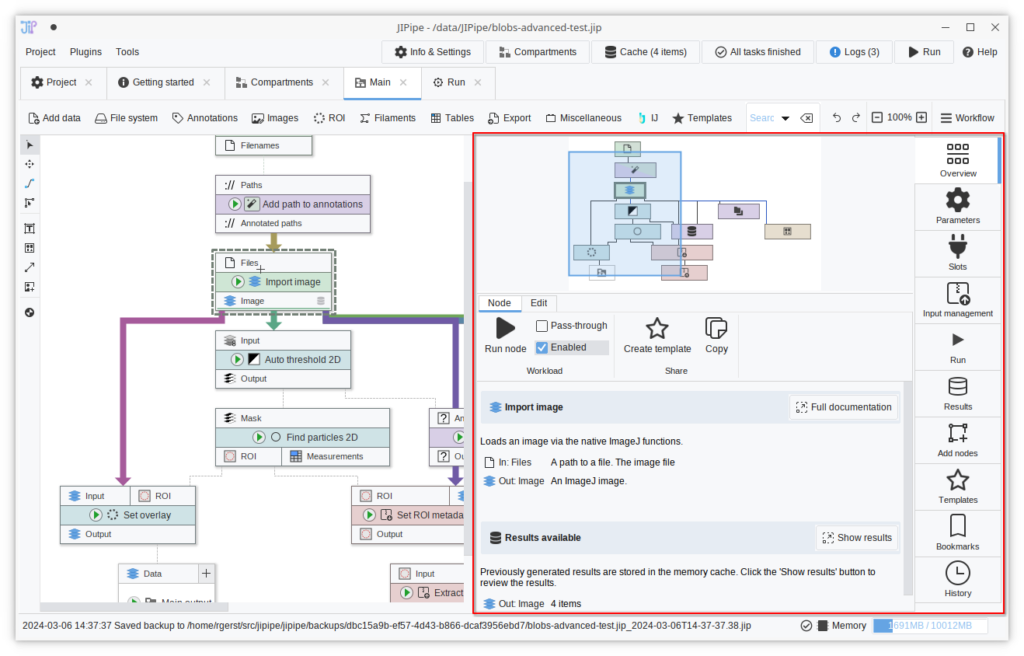
The “Templates” and the “Bookmarks” panels were updated to include an “Add” button that is shown if a node is currently selected.
To make the sidebar more beginner-friendly, “Quick run” was renamed to “Run”, “Cache browser” to “Results”, and “Journal” to “History”.
The bulky notification bars for adaptive and external parameters were condensed into two small buttons next to the parameter panel’s search bar.
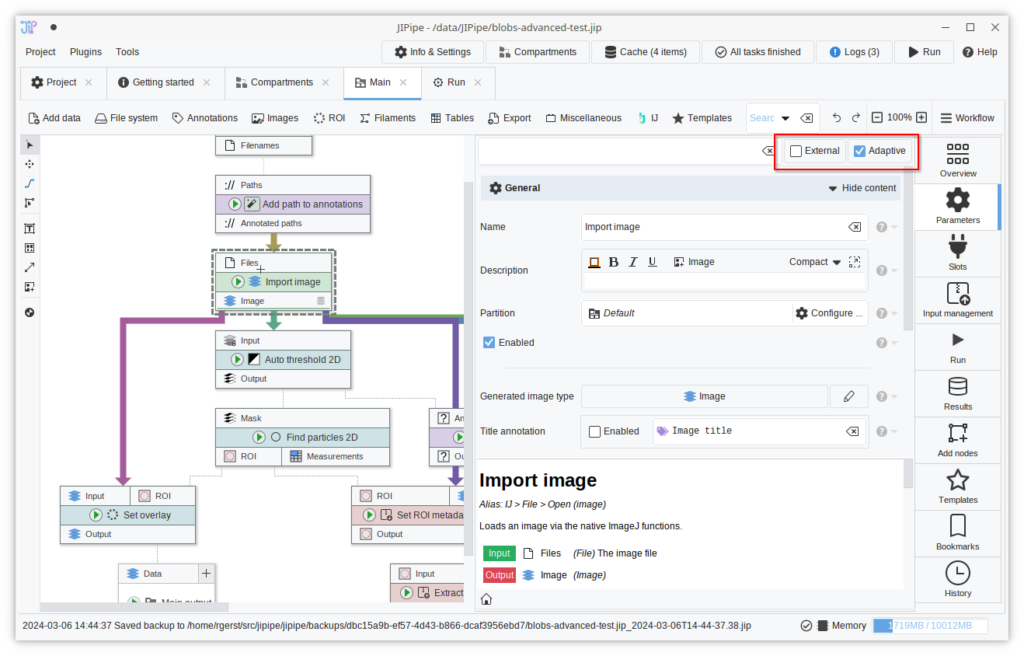
Improved pipeline editor design
The indicator tool tips shown on hovering slots are now displayed as simple highlights.
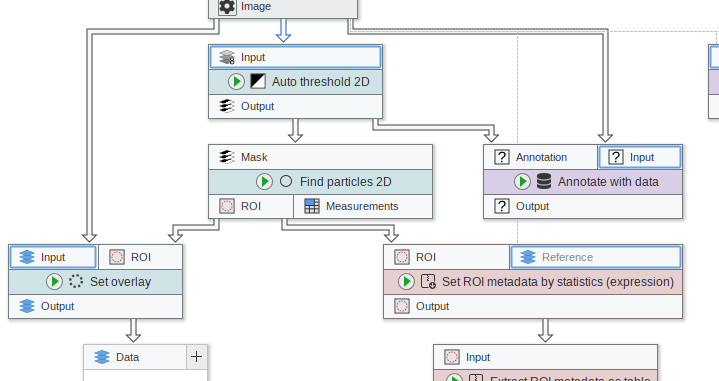
On selecting nodes, all other edges are now muted to make it easier to focus on only the connections related to the selection.
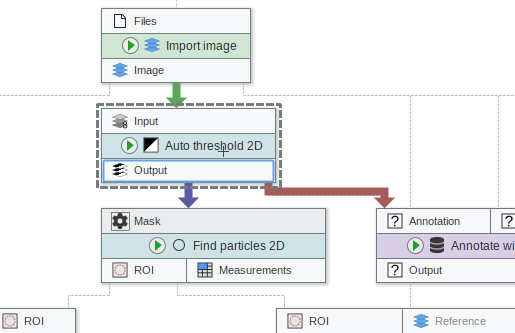
New project settings
The project settings and the project overview pages were merged into one interface that can be conveniently accessed via the “Info & Settings” button at the top right of the JIPipe window.
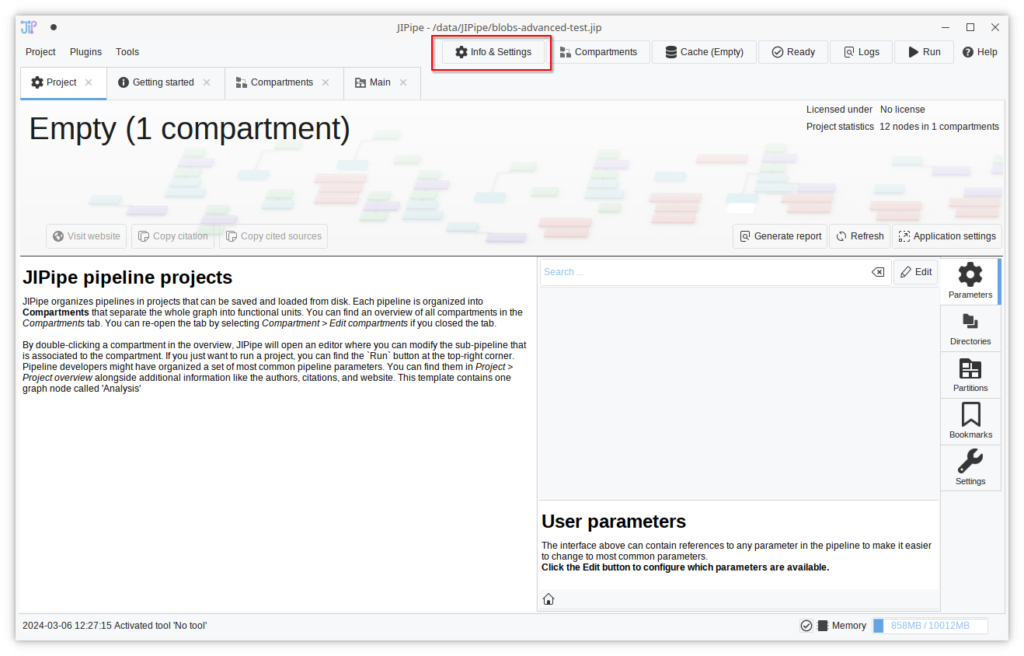
The new project settings screen provides access to all project-wide settings, including
- Referenced parameters from the pipeline
- The list of custom user directories
- The list of graph partitions
- Bookmarked nodes
- The project settings
Shortcuts to the application settings and the project report functionality were added.
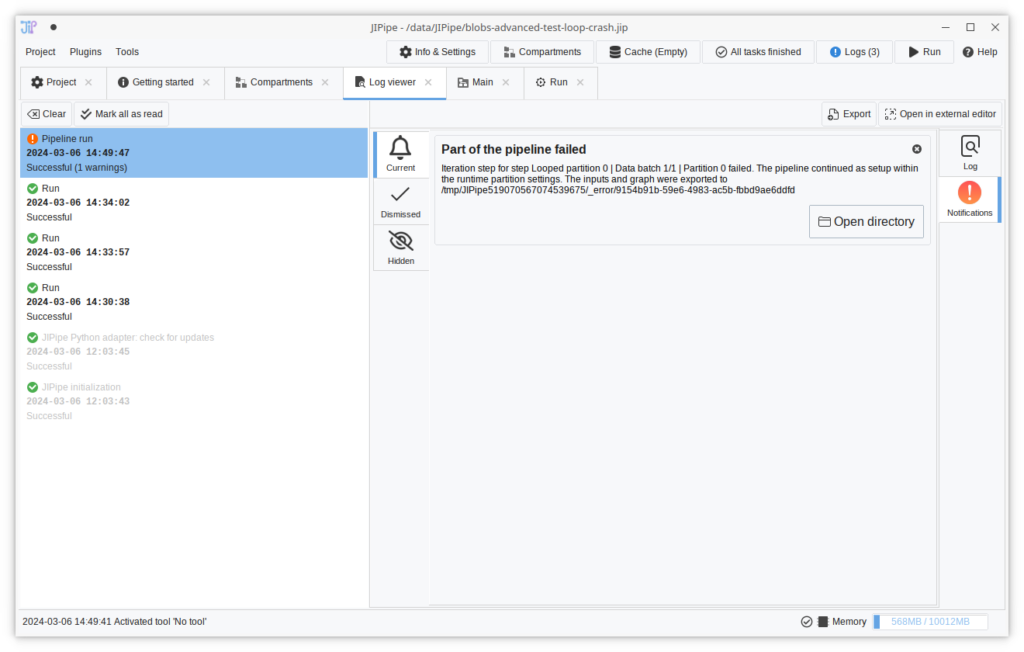
Improved log viewer
JIPipe runs now can notify users about occurrences within the pipeline (e.g., if a part of the pipeline crashed). A new “Logs” button at the top right of the window now provides quick access to the logs and informs users about the presence of new logs. Additionally, the log list was redesigned.
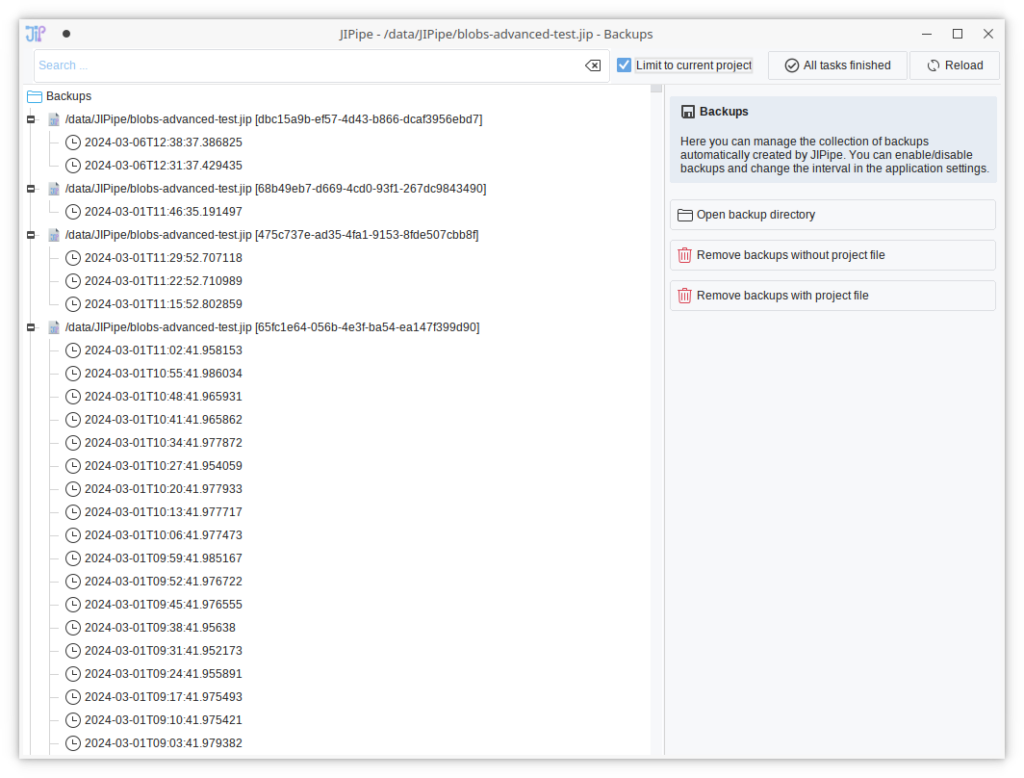
New backup manager
The backup system was completely redesigned and now features a new and fast user interface. Newly created backups store the location of the original file, which is utilized by the manger to organize the backups. Old backups are still available.
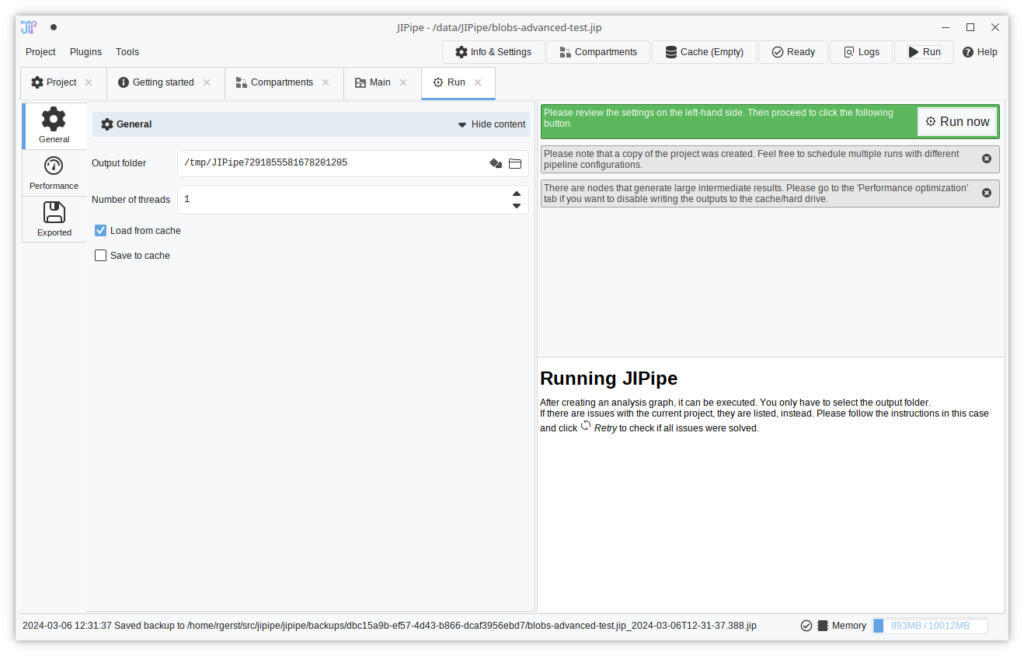
New run setup interface
The interface to setup a full pipeline run was updated to be easier to understand. The user is by default presented with only the basic options, while more advanced settings are hidden behind tabs.
Notifications are shown below the “Run now” button that moved to the right-hand side.
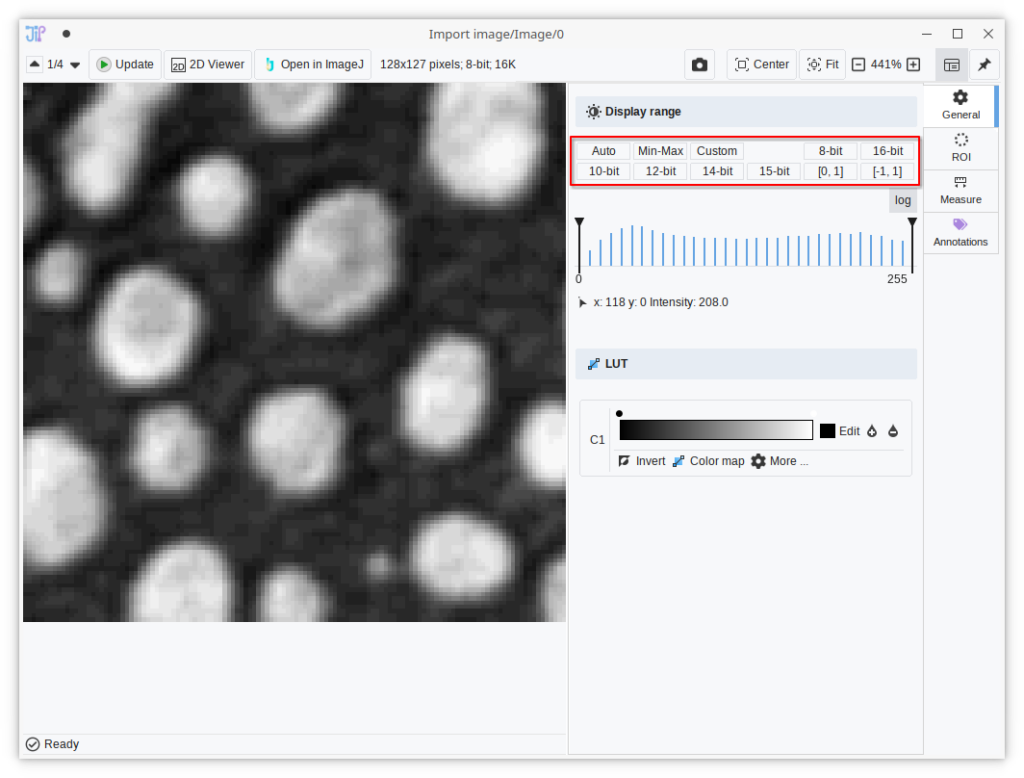
Improved image viewer
The viewer gained right-aligned tabs to make it easier to find the different categories. The display range panel was updated to feature buttons instead of a dropdown to select a display range mode, making the feature more convenient.
Reworked filament visualization
Filaments in 2D are now displayed smoothly even when zoomed in.
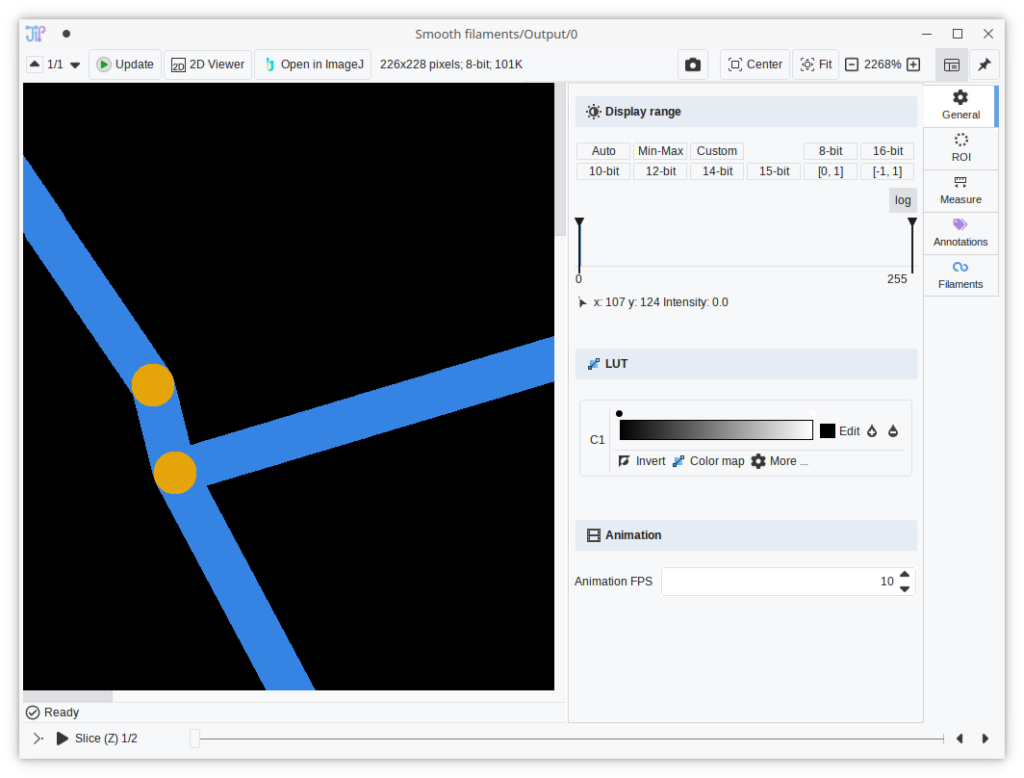
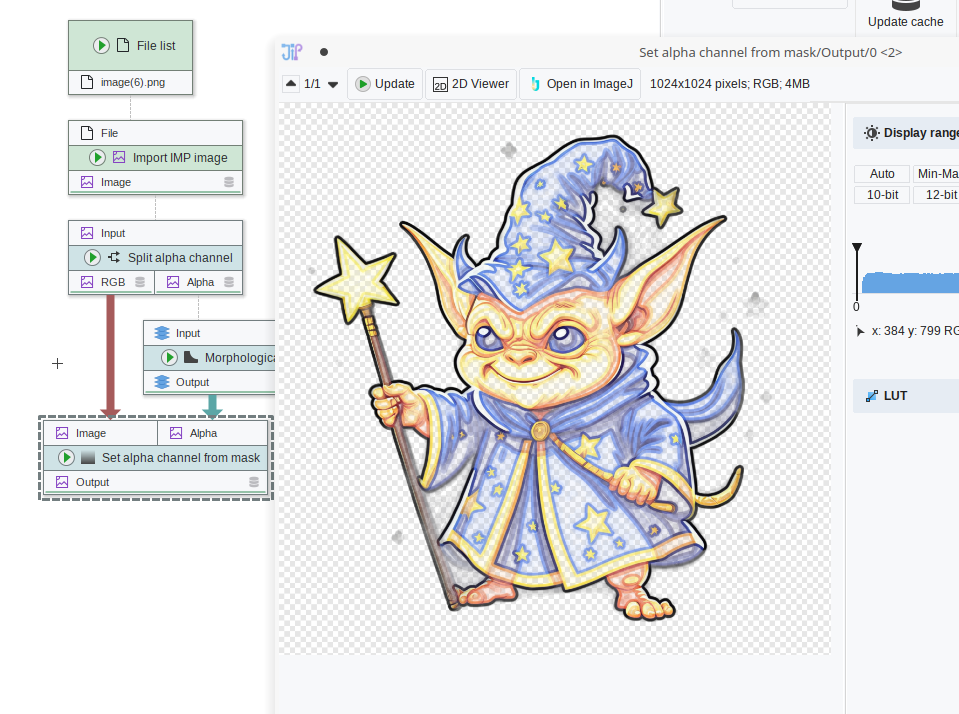
Image Manipulation Pipeline
We started to work on a new plugin that will provide functionality for non-scientific image manipulation. Currently, the new IMP plugin already provides a new image data type and conversion operations that makes it possible to work with images that have an alpha channel. The alpha can be split off (and set via a dedicated node), thus allowing to utilize existing algorithms.
Nodes
- Renamed “Binary skeleton to simplified filaments” to “Binary skeleton to simplified filaments (Analyze Skeleton 2D/3D)” to better indicate how the algorithm works
- New node “Merge labels to bins”
- New node “Crash on inputs” to allow error conditions
- “Create empty image” now can consume a data item used as annotation source
- Pairwise 2D ROI measurements now support the calculation of polygon distances (min/max/avg)
- Weka: Training can now be applied to multiple images
- Filaments to 3D ROI: fixed artifacts caused by enabling the conversion of both vertices and edges into ROI
- CLI was not exiting due to Java Runtime getting stuck on SciJava cleanup
Miscellaneous
- Menu item “Export all nodes as graph JSON” (developer tool)
- Menu item “Export all node properties JSON” (developer tool)
- Menu item “Export all node signatures JSON” (developer tool)
- New expression function STRING_TRIM
- New expression function GET_ITEM_OR_DEFAULT
- New expression function SWITCH_MAP
- UI: Shortcut for adding node Shift+A (like in Blender)
- The data thumbnail API was redesigned: thumbnails are now cached and will not be always recalculated on revisiting data. Please note that thumbnails now load slower due to the lower number of threads (1).
Bugfixes
- Project info screen was not always refreshed completely
- Graph editor: edges in the editor were not scaled according to the zoom
- Data tables (including cache) were affected by concurrency issues that caused unexpected behavior (missing data/freezes) with multi-threaded runs and cache access
- Resolved deadlocks with data storage
- Resolved deadlocks with progress information
- Resolved deadlocks with data tables
- Resolved deadlocks with caching
- Image viewer: display range not working if set manually
- Editing the slots of groups caused losing existing connections
- CSV export was adding spurious .csv extension
- Table export not overriding existing files
- Mutable parameters were not properly duplicated, causing unexpected behavior
- JIPipe could freeze during startup if a dialog is being opened
- Various unexpected cache invalidation cases were resolved
- Resolved issue where JIPipe could not initialize some extensions if a previous extension is incompatible
- NullPointerExceptions with thumbnails in various conditions